
Kurde! Reuse popsuł mi searcha

Reuse wydaje się Świętym Graalem technical writingu, ale w tym artykule chciałbym pokazać, jak ta popularna praktyka może zepsuć wyniki wyszukiwania.
Zacznijmy od początku.
Co to jest reuse?
Reuse, ponowne użycie, lub reużycie, to praktyka pisania raz i używania w wielu miejscach. Stosuje się ją w programowaniu i tworzeniu treści, w tym treści technicznych. Technical writerzy ponownie używają bloki tekstu, artykuły, bądź strony.
Na przykład tworzymy dokumentację do pralek. Nasze pralki to 12 modeli, z których każdy ma od 5 do 30 funkcji. Podstawowe 5 funkcji jest dostępne w każdej pralce a pozostałe to misterna mozaika powtarzających się lub unikalnych funkcji w różnych wariantach. Dla każdego z 12 modeli musimy wydrukować książeczkę z instrukcjami. Używamy więc systemu, który pozwoli nam opisać każdą funkcję raz, a potem poskładać książeczki z kawałków treści jak z klocków. Każdy reusowany fragment to klocek tego samego typu.
Gdzie się sprawdza?
Takie rozwiązanie świetnie się sprawdza kiedy przygotowujemy książeczki do druku, bo każda z nich zawiera komplet informacji. Niczego w niej nie brakuje. Jednocześnie nie ma w niej informacji o funkcjach, które są niedostępne w naszym modelu pralki.
Ten sposób publikacji jest tak powszechny, że wręcz niezauważalny dla użytkownika końcowego. Co wskazuje na to, że sprawdza się bardzo dobrze.
Dlaczego psuje wyszukiwanie?
Wyobraźmy sobie, że instrukcje do pralek są teraz dostępne online. Zostały wrzucone na portal z dokumentacją jako podstrony. Każda książeczka ma nawigację po lewej i jest w pełni kompletnym mini portalem ze wszystkim, czego potrzebuje użytkownik danego modelu.
Jeżeli jedną z podstawowych funkcji każdej pralki jest płukanie, to na naszym portalu mamy stronkę o płukaniu powtórzoną 12 razy. Jeżeli użytkownik wpisze w wyszukiwarkę "płukanie" to te 12 stron będzie konkurować o jego uwagę.
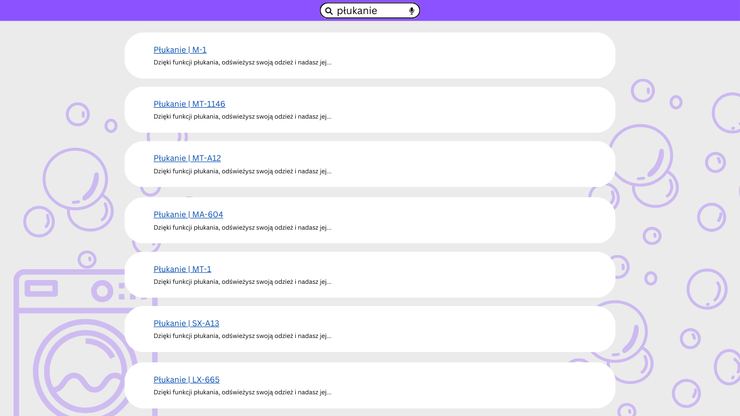
Być może oprócz strony o tytule "Płukanie" jest następna, na przykład "Problemy z płukaniem" albo "Kod błędu: płukanie", ale użytkownik ich tak łatwo nie znajdzie, bo będą dużo niżej albo nawet na drugiej czy trzeciej stronie z wynikami. Poza tym każda będzie w dwunastu kopiach.
Więc w tym wypadku to, co dobre dla drukowania jest niedobre dla wyświetlania w internecie.
Jak rozwiązać ten problem?
Próbowałem znaleźć jakieś przykłady opisujące ten problem. Miałem nadzieję znaleźć jakieś pomysły na jego rozwiązanie. Niestety nie udało mi się. Być może takie artykuły gdzieś istnieją, ale w moich wyszukiwaniach znajdowałem tylko reklamy narzędzi, które pomagają organizować reuse.
W kolejnych sekcjach opisuję rozwiązania, które stosowałem do tej pory w swojej pracy. Do każdego dodaję komentarz wynikający z doświadczenia.
Publikowanie strony tylko raz
Najprostsze rozwiązanie to opublikować każdą stronę tylko raz. Wtedy pojawi się ona w wynikach tylko jeden raz i będzie ją łatwiej spozycjonować. Poza tym użytkownik będzie miał mniej problemów z przeglądaniem wyników wyszukiwania.
Ja osobiście widzę dwa sposoby na osiągnięcie tego celu. Przybliżę je na przykładzie dokumentów w formacie DITA, ale to samo odnosi się do innych generatorow stron statycznych.
Bez reusu
Pierwszy to konstruować nasze dokumenty tak, żeby każda strona występowała w nich tylko raz. Jeżeli mamy wiele map DITA, które tworzą nasze rozliczne dokumenty, nie możemy powtarzać topików między mapami.
Czyli tworzymy osobne mapy dla każdego PDFa i jedną mapę dla naszego portalu HTML. Jeżeli są jakieś elementy wspólne, na przykład nasza strona o płukaniu, to umieszczany ją w mapie dla HTMLa tylko raz. To oznacza, że opublikujemy jedną paczkę stron, która opisuje wszystkie możliwe funkcje wszystkich modeli pralek. Żeby pomóc użytkownikowi, na każdej stronie piszemy do których modeli pralek ta strona się odnosi.
Taka forma publikacji może jednak czasem namieszać użytkownikowi w głowie. Może to efektywnie doprowadzić do takiej sytuacji jak drukowanie jednej instrukcji dla wszystkich modeli pralek i zaznaczanie przy każdej funkcji listy modeli, w których jest dostępna. Nie jest to idealne rozwiązanie, ale dosyć często spotykane w materiałach drukowanych.
Skoro jesteśmy online, to możemy dać użytkownikowi przyciski z filtrami, które "ukryją" strony do "innych modeli". Ale to wymaga od naszych użytkowników głębokiej znajomości naszych produktów i eksperckiego podejścia do korzystania z naszej strony (power user!). A to z kolei nie jest coś, czego powinniśmy wymagać od naszych użytkowników.
Single sourcing
Drugi to przetwarzać mapy DITA inaczej dla druku (PDF) a inaczej do internetu (HTML). Dla PDFa powtarzamy tę stronę w każdej mapie, która jej potrzebuje. Z tego powstają oczywiście osobne PDFy i powtarzająca się strona nie przeszkadza użytkownikowi.
Natomiast dla HTMLa używamy warunków w mapie, które nie powtarzają tej strony tylko umieszczają link do niej. Czyli wygenerujemy osobną paczkę stron dla każdego modelu, ale w żadnej paczce nie będzie naszej strony o płukaniu. Ta będzie w osobnej paczce zawierającej wszystkie funkcje wspólne.
<topicref href="plukanie.dita" platform="print" />
<reltable>
<relheader>
<relcolspec type="task"/>
<relcolspec type="reference"/>
</relheader>
<relrow>
<relcell>
<topicref href="plukanie.dita"/>
</relcell>
<relcell linking="targetonly">
<topicref href="uzyteczne-linki.dita"/>
</relcell>
</relrow>
</reltable>
To trochę karkołomne rozwiązanie, ale powinno zadziałać. W tym przykładzie
topicref kierujący do plukanie.dita pojawi się tylko jeśli akurat budujemy
PDFa a nie pojawi się w HTMLu.
reltable i zawarty w niej atrybut linking="targetonly" sprawi, że na stronie
"Użyteczne linki" pojawi się link do "Płukanie", ale nie odwrotnie.
BONUS: magiczna technologia
Trzeci, magiczny sposób to użyć mechanizmu publikacji, który wykracza poza typowe generowanie stron statycznych. Nie możemy polegać na prostym transformowaniu mapy DITA na strony HTML. Zamiast tego musimy zbudować system, który w jakiś sposób posortuje z zdeduplikuje nasze strony.
Taki system to nie lada wyzwanie i nie sądzę, żeby taki gdziekolwiek istniał. Przynajmniej ja takiego jeszcze nie widziałem, chociaż możliwe, że wkrótce rozpoczniemy nad nim pracę w moim obecnym zespole. Jeżeli to się uda, to postaram się podzielić ze światem naszym osiągnięciem.
Filtrowanie
Jeśli nie możemy publikować stron tylko raz, kolejną najlepszą opcją jest filtrowanie. Dodajmy po lewej stronie panel z checkboxami i pozwólmy użytkownikowi wybrać, o której wersji pralki chce poczytać. To nie jest idealne rozwiązanie, bo o ile w wypadku pralki, użytkownik prawdopodobnie wie jaki model posiada, o tyle w bardziej skomplikowanych systemach wybory filtrów stają się trudniejsze. Może dojść do tego, że użytkownik nie będzie wiedział jaki "produkt" wybrać, ani co mamy na myśli rozróżniając "wersję" od "wydania". Albo czym się różni "komponent" od "części".
Kolaps
Ostatnie rozwiązanie, które widziałem w akcji, to zgrupowanie podobnych wyników. Czyli jeden wynik o tytule "Płukanie" a pod spodem zwijany akordeon z listą innych wersji strony o płukaniu.
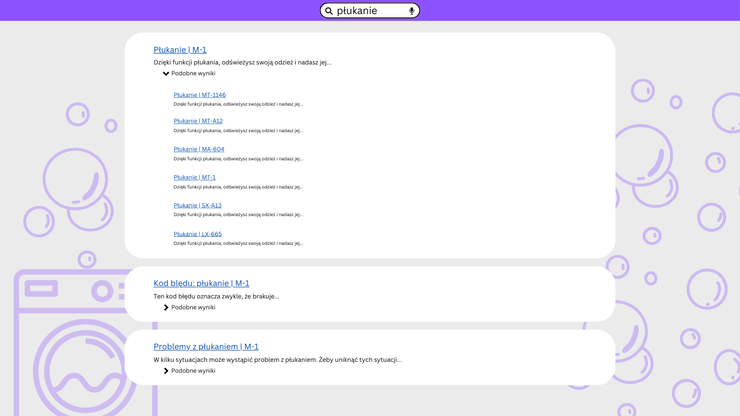
To rozwiązanie ma swoje słabe strony, na przykład to, że rozwijana sekcja może stać się bardzo długa i przez to mało pomocna. Jeżeli spróbujemy ją wyposażyć w jakieś kontrolki pozwalające wybrać model pralki, to znacznie zwiększymy jej poziom skomplikowania.
Innym problemem jest to, że użytkownicy mogą nie zrozumieć, co daje ta sekcja i jak jej powinni używać. Dla nas jest oczywiste, że są w niej wymienione wszystkie inne instancje tej samej strony w innych modelach pralki. Ale to co dla nas jest oczywiste wynika z tego, ze znamy strukturę własnej dokumentacji.
Generalnie to rozwiązanie nie jest absolutnie najgorsze. Warto go spróbować i zebrać feedback od użytkowników.
Nie ma złotego środka
Poradzenie sobie z tym problemem na pewno będzie wymagało głębokiej analizy i dostosowania się do wymagań użytkownika. Nie będziemy w stanie znaleźć uniwersalnego rozwiązania dla każdego zbioru dokumentacji. Więc jeżeli ktoś twierdzi, że ma uniwersalne rozwiązanie, podejdźmy do niego z odrobiną rezerwy.